Info
This article was originally published on LinkedIn in 2021, and is being republished here to centralize previous writings in one place. Links and information may be broken or out of date.
For a while now, I’ve been wanting to do some kind of programming project that relies on the web in some capacity. The opportunity has never really presented itself in a way to me that was appealing or within scope, especially back when I was working on game projects exclusively. Now that I have begun to take a much stronger interest in general software engineering projects though, I found myself searching once again for something that I could attempt on this front.
Web scraping is something that I’ve been interested in for a while, but a majority of demonstrations I had come across didn’t really appeal to me, or seemed morally questionable (at best) in how they were utilized. An opportunity eventually presented itself for me to try this out in a project through the game League of Legends. While I am not personally a very involved player, my friends are - so why don’t I do something nice and create a way for them to be notified of new Patch Notes that release for the game? With this idea in mind, I went about creating a bot to do so via Discord.
The high-level explanation of what we want to achieve is as follows: around every 10 minutes or so, we check the League of Legends website for any new articles that have been posted onto the Patch Notes page, which detail all changes that have been made in that current update. If any of these articles or entries pulled from the page are new and have not been posted before, then we take that particular post, and post it to Discord, ideally within a dedicated channel just for it.
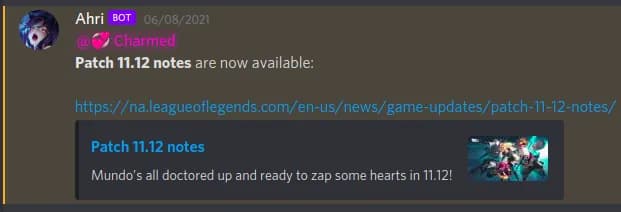
In order to pull this off, the bot was written in Python, and in order to be able to scrape patch note entries, a HTML parsing library called Beautiful Soup was used to simplify the process. How it was used in order to scrape the Patch Notes page is very straightforward - If you use the Inspect Element function on a webpage in your browser of choice, you’ll be able to view the complete HTML layout and content of it and even make your own changes locally to the page’s appearance and content through it; You may even remember doing this yourself for a joke at some point.
Once we are able to view this, what we can do is start to look for any relevant HTML elements or classes that represent the articles that we are looking for. While classes are preferred for helping narrow it down, they unfortunately appeared to be inconsistently named between web page visits with no clear pattern of change to the class’ name, at least at the time of writing. Luckily, we were still able to identify any articles directly by searching for <a> tags that contained a href attribute, which happened to be enough for finding all 6 articles that would be displayed. From there, the structure of any 1 of these entries would be as follows in HTML:
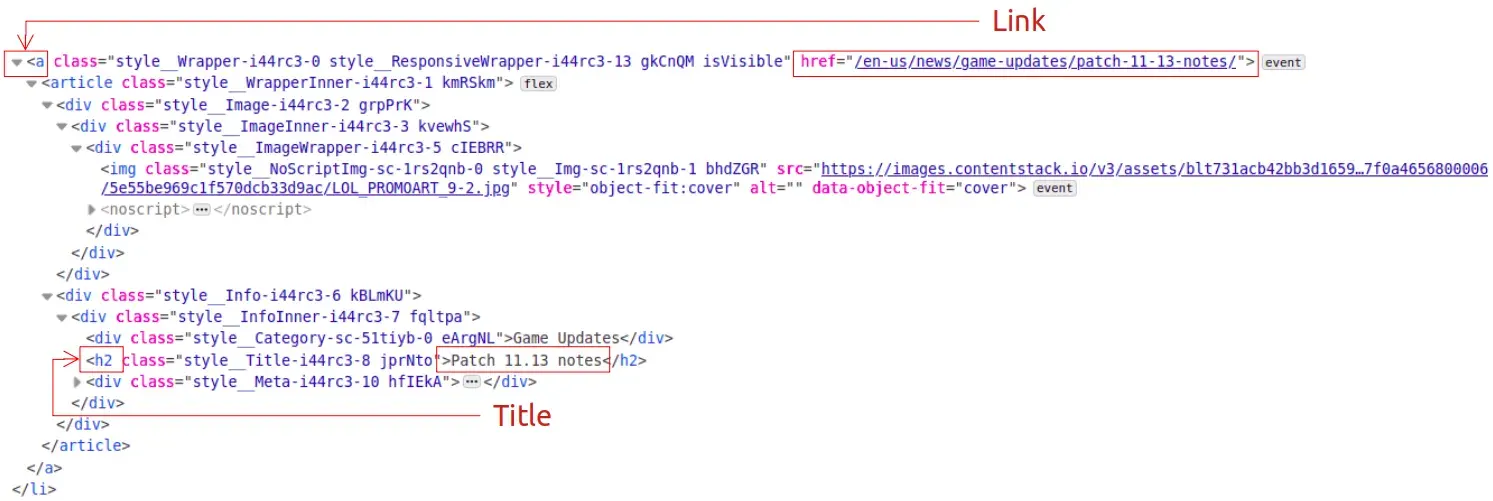
As shown above, the title of the Patch Notes post in question, as well as the actual link to it are all that we are really after. From this, we see that we can simply read the contents of the href attribute to obtain the portion of the URL we needed, and that the text found in the first h2 tag encountered is the title. With that, we can now just pull these individually in code for every article that we come across, and hold on to it for later. With Beautiful Soup, this can be done in just a few lines of code for our use case:
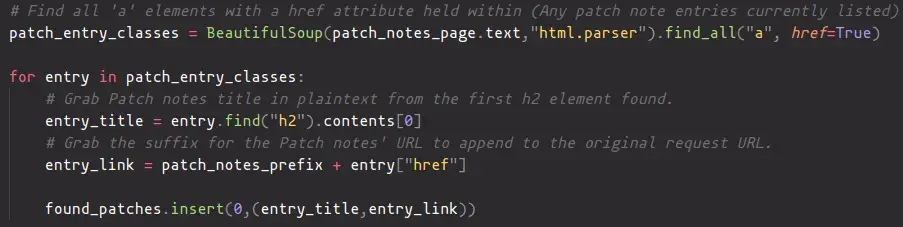
Now that we have a list of of the entries found on the page and their URLs, we want to make sure that what we have found is actually new, as in we haven’t actually posted it before. It probably wouldn’t be fit for purpose if the bot just posted the same repeating sequence of entries every time it checks for it, so that now meant pruning the list of any entries that have a URL which has been posted already, which we can keep track of by simply writing them to a file held on disk, and consulting it again when we need to later on. With that we are able to successfully pull entries down and prune existing ones, the next order of business was to post these to Discord directly once we had them.
When it comes to sending messages to Discord, they provide a solution for doing so which really trivializes the whole process – Webhooks. These are dedicated URLs that can be created for a server for the purposes of posting messages, although they are restricted to only this - they cannot read or respond to messages and events from other human users like traditional Discord bots can. Luckily, we do not need to worry about this for our use case, and can send messages in code by making a POST request. The really nifty thing that should also be said about Discord’s webhooks is that parameters such as the display name, image and channel the bot will be posting under can all be adjusted in the client, all of which leaves us with a minimal amount of code to actually write.
With a bot ready to go, my next concern was how to deploy it. Leaving it running on a machine I regularly use was an option, but in practice I knew that this would be less than ideal, especially since I like to close windows I’m not actively using and dual-boot operating systems frequently. Another option I had considered was to host the bot in the cloud or on a rented server space, but this felt too expensive and overkill for such a small project like this. Ideally, I wanted something that I could just plug in, and leave alone. While the bot does output some information if desired, I knew that it could just run headless as long as it had a way to run the Python script on its own. In comes the Raspberry Pi.

If you have not heard of a Raspberry Pi before, they are a very cheap line of single-board computers initially created to provide an easy and cost-effective way to introduce children to Computer Science and Programming in schools. No larger than a credit card physically, they only require a display, keyboard, mouse and SD card with an Operating System loaded onto it in order to have a fully functioning machine going, although this is by no means required if you’re looking to do something else with it. Depending on the model used, a wide array of other connections are also available on the board itself, making it applicable for a wide range of uses such as robotics, DIY, IoT devices, home servers on a budget, cybersecurity, or even just running emulators!
The Raspberry Pi Foundation provides an officially supported Linux distribution called Raspberry Pi OS (Previously named Raspbian, as it is based on Debian, another popular Linux distribution) which at the time of writing, is still supported for all models that currently exist on the market.
Because of how customizable Linux is, I knew that it would just be a matter of getting the bot’s files onto the Pi, and having it boot into the command line to run it automatically when it is powered on. I could also potentially include a shell script that allows the bot to be run again if an error is ever encountered, allowing it to effectively restart itself and run unsupervised. All that I would need to do once everything was set up was to ensure that it had a continuous power source, either from a USB wall adapter or via a power bank, and that it has some kind of Wi-Fi or ethernet connection established in order to make requests successfully.
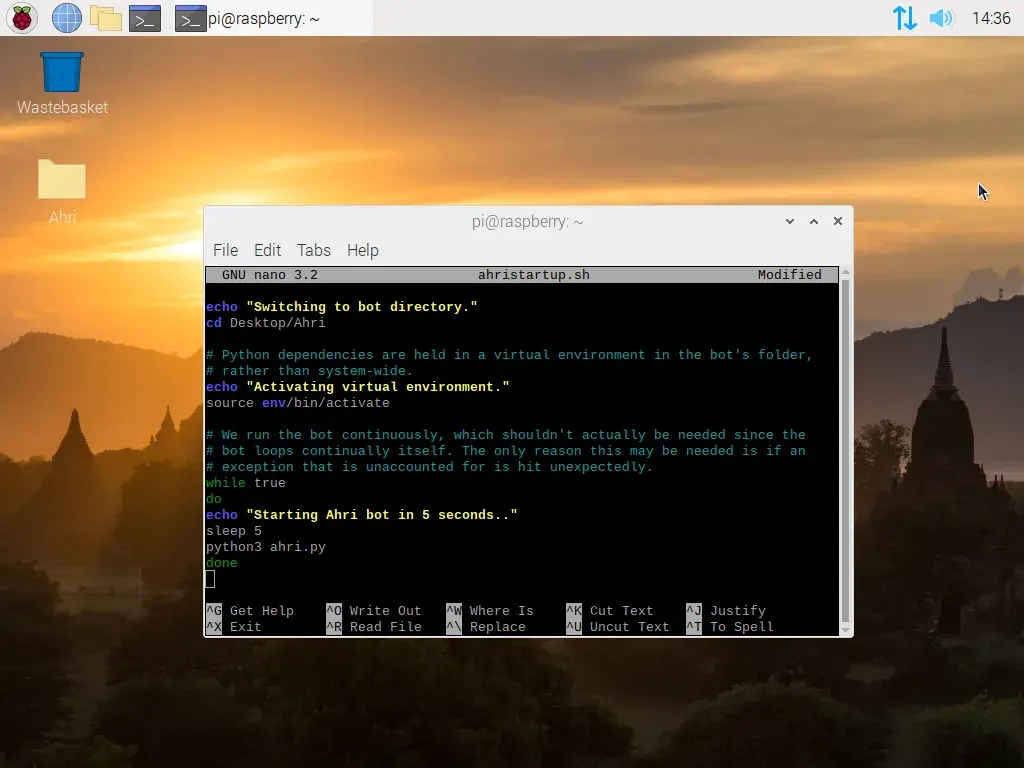
To have everything run automatically when the Pi is powered on, I wrote a basic bash script that switches into the directory where the bot’s files are kept, ensure dependencies will be recognized by initializing its virtual environment, and to then run it in a continuous loop. While the bot is already programmed to loop continuously in order to check for updates, in the event that an error or exception is encountered that causes it to terminate, it should automatically restart itself again and continue as normal, so long as there isn’t some kind of other major issue that needs addressing.
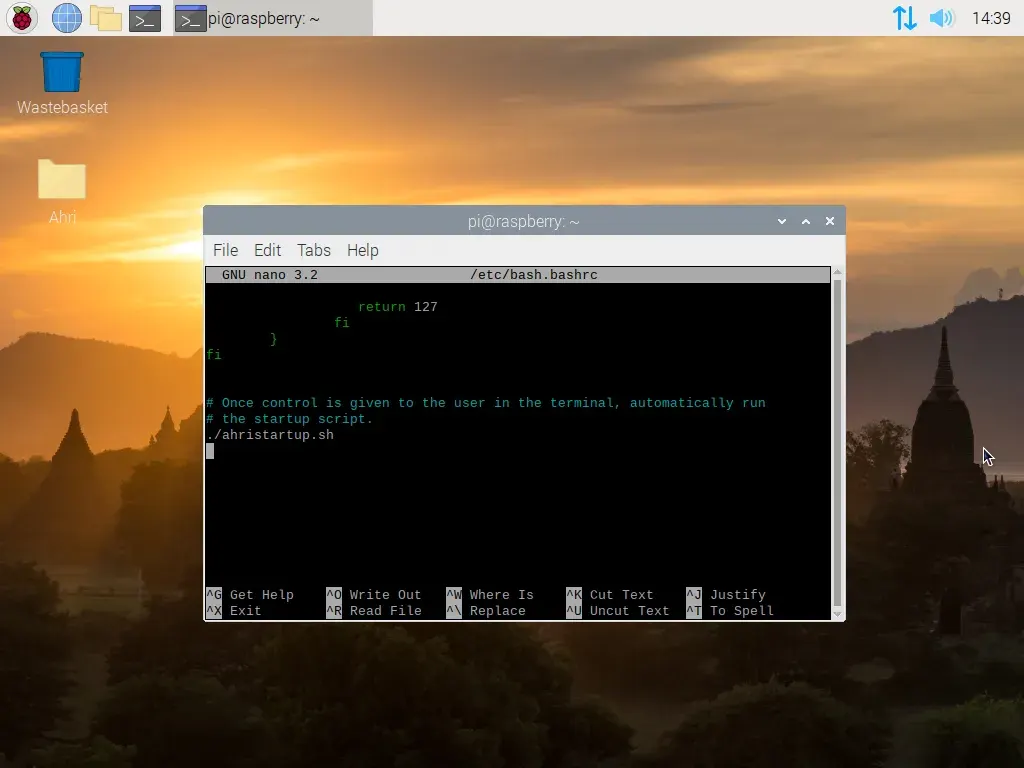
Because Raspberry Pi OS can be configured to boot straight into a Command Line Interface (CLI) rather than a traditional Desktop, we can get our script to run as soon as control is given to the user in the terminal by placing a call to run it in /etc/bash.bashrc, which will run everything inside it when a new terminal session is created.
After that, we can check if the script is running by simply opening a new terminal session.
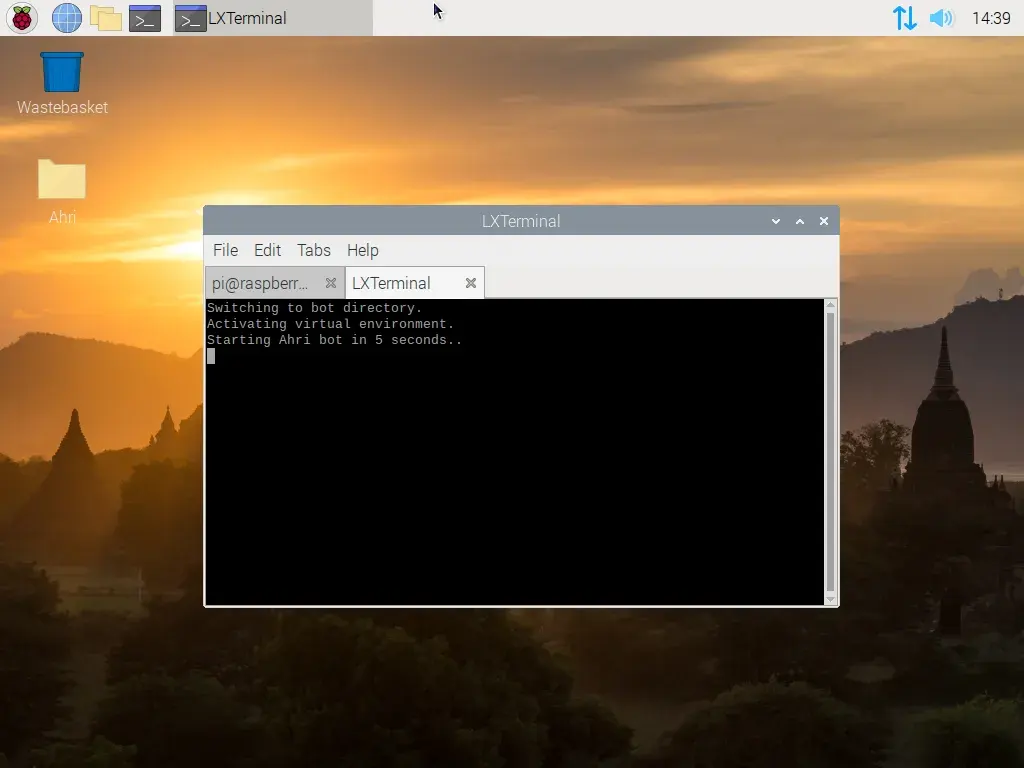
And once again, we need to make sure that we configure the Raspberry Pi to boot into the command line on its own.
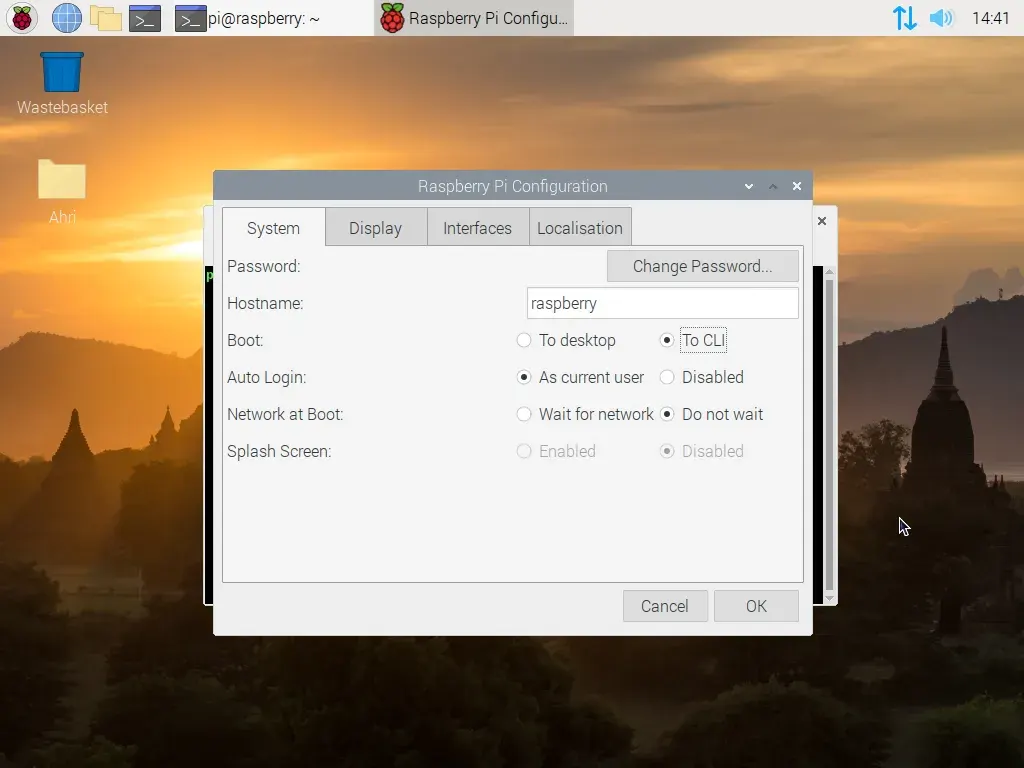
Once we reboot the Pi, it will automatically run the script, and the bot in turn, meaning that it can now be run headless as planned.
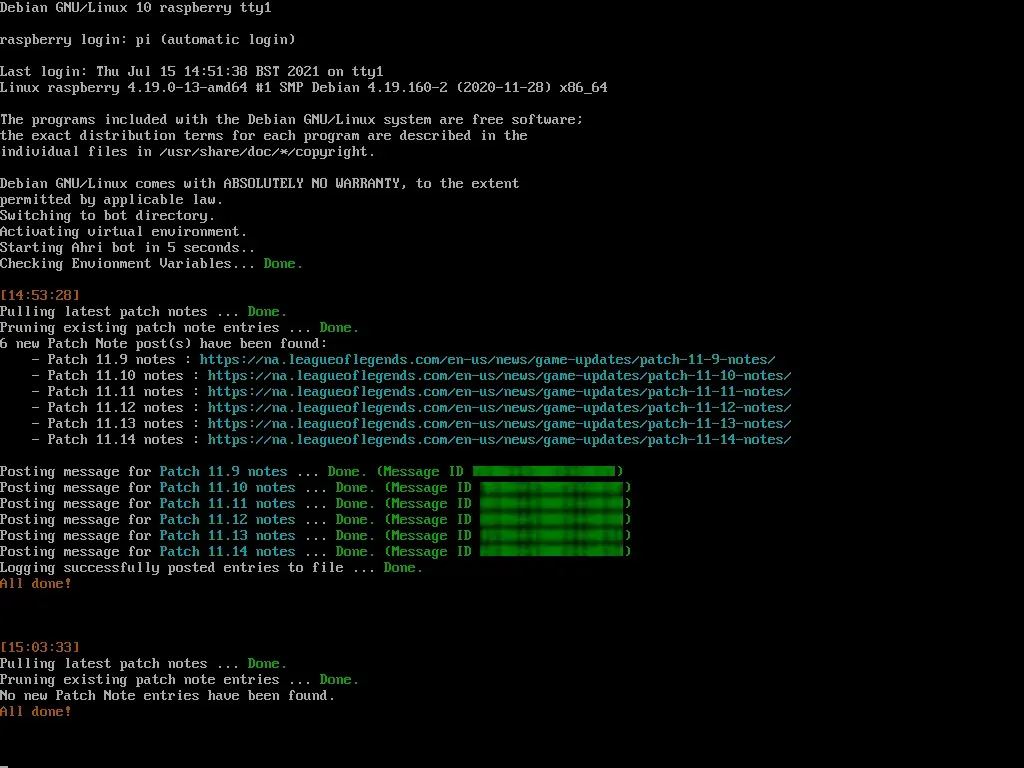
With this now working, we have a web-scraping Discord bot that is running headless as desired - I can now leave this powered on somewhere, and forget about it. If I ever need to change something in the future, it simply becomes a matter of connecting a display and keyboard to it!
There are a number of ways that I could continue to expand upon this bot, as it is held back by a few problems that I know I will have to ultimately address in the future due to its nature. For example, in the fairly likely event that the HTML structure of the League of Legends website changes, the bot may not be able to successfully pull down new updates any more without changes in code to accommodate it, a fault which may not be recognized immediately as someone would have to notice that the bot is not posting updates to begin with. This could be remedied in the future through the introduction of something like a “heartbeat” signal that is continually present as the bot continues to function, making these problems quicker to identify when they occur.
Despite these shortcomings, I would still consider this project a success for what I initially set out to do, and for the last couple of weeks at the time of writing, the Raspberry Pi I’ve set up has been going strong, and working as intended. It is incredibly fulfilling to take something I’ve made and give it some kind of real world use, even if it is just to automate the process of checking for new game updates, and now that I’ve gotten my feet wet with this, I’m excited for what the future holds in what I could explore next.
If you are interested in poking around the bot’s code, or even deploying this in your own Discord server, you can find it over on GitHub.